1. Wprowadzenie do SPSS | Tworzenie baz danych | Podstawowe operacje na danych | Tworzenie wskaźników zmiennych
Sylabus i cele zajęć #1
| Treści programowe | Literatura obowiązkowa | |
|---|---|---|
| 1 | Wprowadzenie do SPSS: interfejs, tworzenie bazy danych, podstawowe operacje, wskaźniki zmiennych. | Bedyńska & Cypryańska (2013), Drogowskaz 1 (s. 48–71, 114–130). Wydawnictwo Akademickie Sedno. Józefacka, Kołek, Arciszewska-Leszczuk (2023), Tom 1 (s. 105–114). WN PWN. |
- Poznasz interfejs SPSS i jego podstawowe elementy.
- Nauczysz się tworzyć bazę danych i definiować zmienne.
- Będziesz potrafić wykonywać pierwsze operacje na danych (rekodowanie zmiennych, obliczanie na zmiennych).
- Dowiesz się, czym są wskaźniki zmiennych i jak je tworzyć.
SPSS = Statistical Package for Social Sciences
Pakiet wykorzystywany powszechnie w naukach społecznych: psychologii, socjologii, pedagogice, ale też służy do analizy danych z systemów operacyjnych, transakcyjnych, danych sprzedażowych… zastosowanie wykracza poza zagadnienia sugerowane nazwą pakietu.
Wprowadzenie do SPSS
Interfejs SPSS
Po uruchomieniu programu SPSS zobaczysz okno główne, które składa się z dwóch podstawowych widoków:
- Widok danych (Data View) – tutaj wprowadzamy dane, każdy wiersz to jeden przypadek (np. uczestnik badania), a każda kolumna to zmienna.
- Widok zmiennych (Variable View) – tutaj definiujemy właściwości zmiennych (np. nazwa, typ, etykiety, wartości).
Na górze znajduje się pasek narzędzi i menu główne, w którym znajdziesz wszystkie najważniejsze opcje analizy (m.in. Analiza, Przekształcenia, Wykresy).
Na dole okna możesz przełączać się pomiędzy widokiem danych i widokiem zmiennych, w zależności od tego, czy chcesz pracować na danych czy definiować zmienne.
Poniżej przykład interfejsu SPSS z zaznaczonymi kluczowymi elementami:
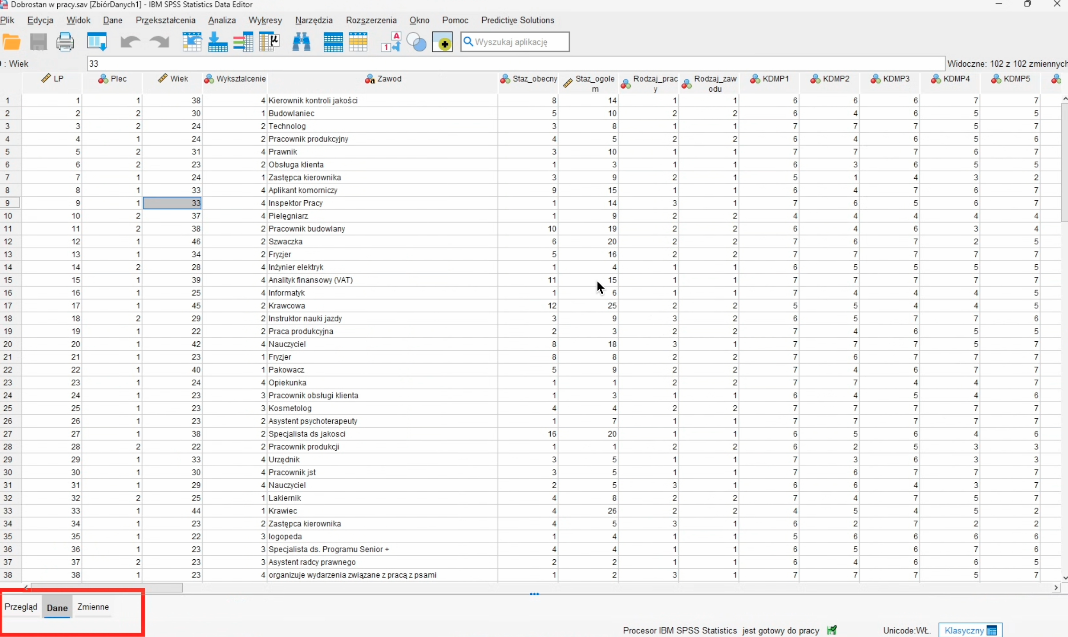
Widok zmiennych
Widok zmiennych w SPSS działa jak słownik danych — to tutaj szczegółowo opisujemy wszystkie zmienne w pliku: ich nazwy, typy, sposób kodowania i poziom pomiaru.
Dlaczego to ważne?
Dobrze uzupełnione informacje o zmiennych ułatwiają orientację w pliku i poprawiają czytelność raportów wyników analiz.
Najważniejsze właściwości zmiennych
Nazwa zmiennej: krótka, precyzyjna i bez spacji (np. wiek, plec, dobrostan).
Typ zmiennej: Numeryczny (liczbowy) — umożliwia wykonywanie obliczeń lub Łańcuchowy (string) — tekstowy, służy np. do opisu zawodu.
⚠️ Uwaga: SPSS przeprowadza analizy tylko na liczbach!
** Etykieta**: pełniejszy opis zmiennej, np. całe pytanie z kwestionariusza.Dzięki etykietom raporty są bardziej zrozumiałe.
Wartości : kodowanie odpowiedzi liczbowych, np.:
1 = kobieta, 2 = mężczyzna
1 = bardzo rzadko, 2 = rzadko, 3 = przeciętnie, 4 = często, 5 = bardzo często
Poziom pomiaru: określa, jakiego rodzaju jest zmienna:
- Nominalna → kategorie bez uporządkowania (np. płeć, zawód)
- Porządkowa → kategorie z uporządkowaniem (np. poziom wykształcenia)
- Ilościowa → zmienne liczbowe (np. wiek, staż pracy)
Najważniejsze właściwości zmiennych to:
- Nazwa zmiennej — krótka, precyzyjna i bez spacji (np.
wiek,plec, nazwa podskali).
- Typ zmiennej — numeryczny (liczbowy) lub tekstowy (string). Uwaga: program rozumie i robi obliczenia jedynie na liczbach.
- Etykieta — gdy nazwa zmiennej jest zbyt krótka, to etykieta przedstawia bardziej szczegółowe informacje o tym, co oznaczają zmienne (np. pełne brzmienie pytania czy stwierdzenia w ankiecie)
- Wartości — kodowanie wartości liczbowych (np. 1 = kobieta, 2 = mężczyzna lub 1 = bardzo rzadko, 2 = rzadko, 3 = przeciętnie 4 = często, 5 = bardzo często).
- Poziom pomiaru — skala zmiennej:
- Nominalna (np. płeć, zawód),
- Porządkowa (np. poziom wykształcenia),
- Ilościowa (np. wiek, staż pracy).
- Nominalna (np. płeć, zawód),
Przykładowy widok zmiennych w SPSS:
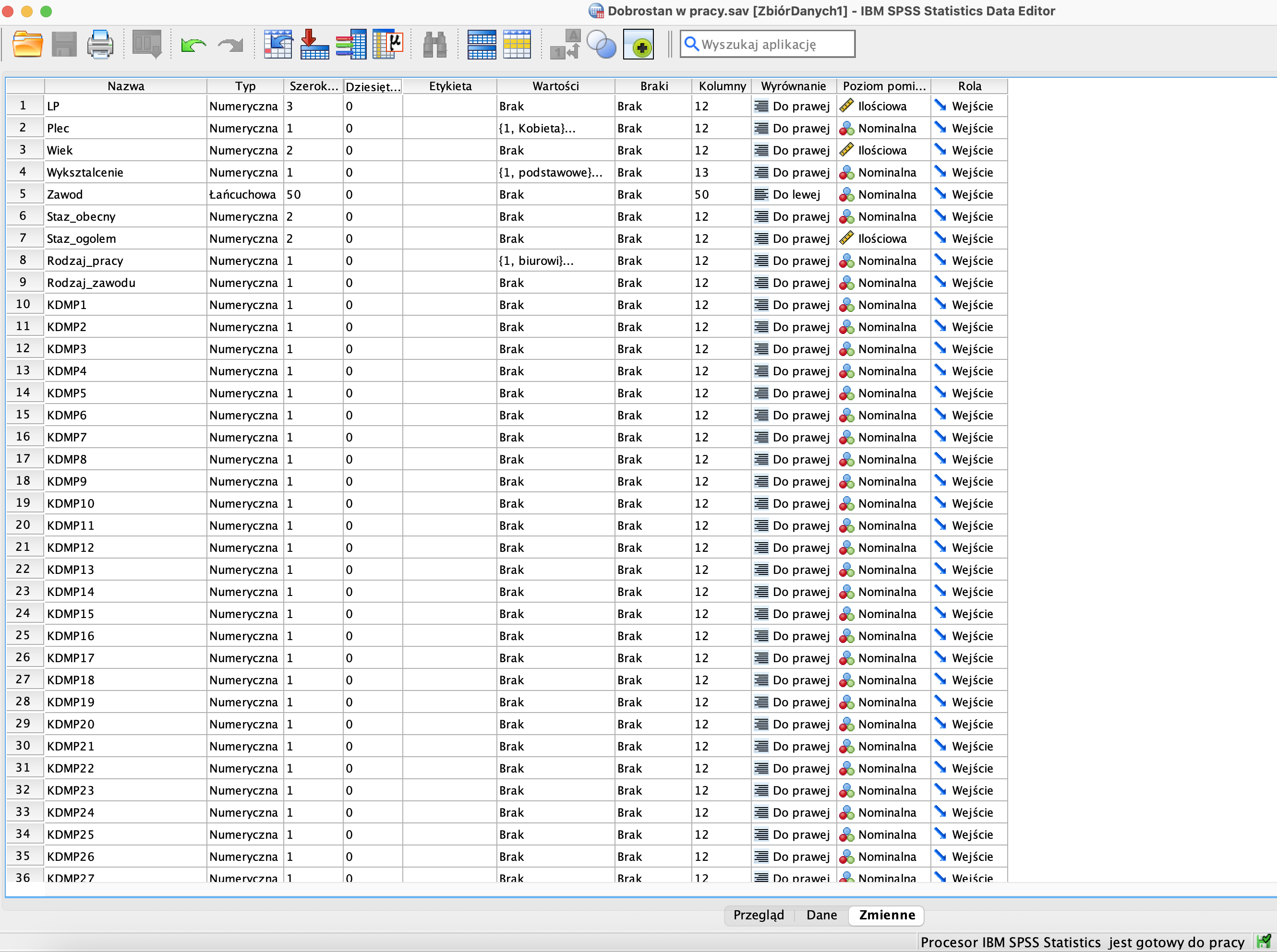
👉 Wskazówka: Poprawne zdefiniowanie zmiennych to podstawa każdej analizy.
Zła definicja (np. traktowanie zmiennej jakościowej jako ilościowej) prowadzi do błędnych wyników.
Widok danych
Poniżej przykład interfejsu SPSS z widokiem danych i zaznaczonymi kluczowymi elementami:
Dane to informacje o osobie badanej, a każda pojedyncza informacja stanowi osobny element danych. Wpisując dane o osobie badanej, należy pamiętać o tym, że wyniki jednej osoby muszą znaleźć się w jednym (i tylko jednym) wierszu. Nawet jeśli badamy tę samą osobę dwukrtonie tym samym testem, to jej odpowiedzy z testów muszą znaleźć się w jednym wierszu w sąsiadujących kolumnach - najpierw wyniki pierwszego pomiaru, potem wyniki drugiego. Kaźdy kawałek informacji o tej osobie stanowi zmienną.
W SPSS każda odpowiedź lub pomiar jest osobną zmienną, a każdy badany to jeden wiersz w tabeli danych.
Dane surowe to wszystkie wyniki zebrane w badaniu w nieprzetworzonej formie – takie, jakie pochodzą bezpośrednio od osoby badanej (np. odpowiedzi w kwestionariuszu, punkty w teście, czas reakcji w eksperymencie).
Kodowanie danych to proces przekładania tekstowych informacji o osobie na informacje liczbowe, np. płeć.
⚠️ Pamiętaj: Osoby badane umieszczamy w wierszach, zmienne w kolumnach, 1 osoba badana = 1 wiersz
Tworzenie baz danych
Przy tworzeniu baz danych w programie SPSS należy pamiętać o kilku istotnych regułach:
- Reguła 1: Najpierw opisujemy zmienne, ich etykiety i wartości w zakładce ZMIENNE. Dopiero potem wprowadzamy dane.
- Reguła 2: Przy wprowadzaniu danych należy ponumerować ankiety / osoby badane. Dlatego pierwsza zmienna to informacja o numerze OB.
Poszczególne kroki, by wprowadzić dane ankietowe do programu:
Krok 1: W zakładce ZMIENNE i wpierwszym wierzu kolumny NAZWA wpisujemy zmienną dotyczącą numeru osoby badanej (np. nob). W kolumnie etykieta opisujemy zmienną (nadajemy pełną nazwę zmiennej) “Numer osoby badanej”.
Krok 2: Kolejne zmienne pochodzą z narzędzia badawczego, np. ankiety lub testu psychologicznego.
Krok 3: Po zdefiniowaniu zmiennych przechodzimy do zakładki DANE. Możemy wprowadzać dane z ankiety, pamiętając, ze każdy wiersz = jedna osoba badana
Krok 4: Zapisz zmiany w pliku!
Przyjrzyj się ankietom z badania zadowolenia z pracy i innych aspektów działalności zawodowej i stwórz bazę danych na jej podstawie.

- Otwórz SPSS i stwórz nowy plik danych.
- Wprowadź zmienne
- Wpisz zebrane dane
- Nie zapomnij zapisać pliku!
Przykładowe rozwiązanie dla pozycji: Firma: państwowa/prywatna
Wprowadź NAZWĘ: Firma Wpisz ETYKIETĘ: firma, w której pracuje osoba badana Zdefiniuj WARTOŚCI: (wartość) 1 - (etykieta) państwowa; (wartość) 2 - (etykieta) prywatna
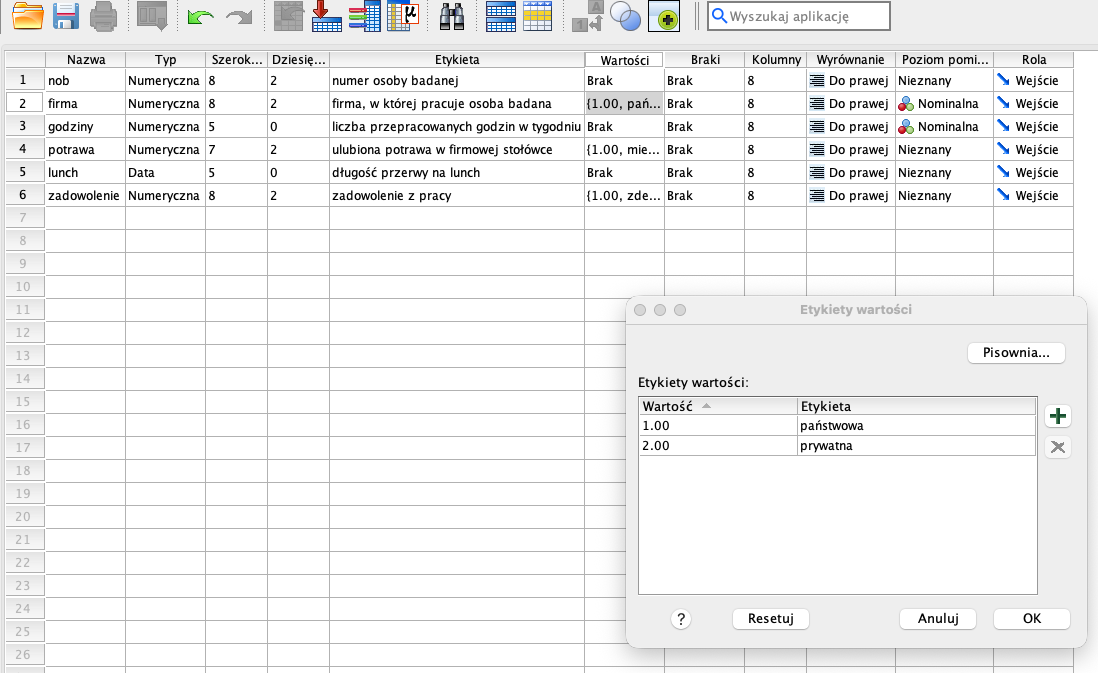
Podstawowe operacje na danych i tworzenie wskaźników ziemnnych
Zmienna może mieć wiele różnych wskaźników. Przykładowo, jeśli chcemy zbadać poziom ekstrawersji, możemy zastosować różne wskaźniki, np. zbadać ludzi testem EPQ-(R) - Eysenck Personality Questionnaire-Revised - opartym na teorii osobowości eysencka (Eysenck, Eysenck i Barrett, 1985) lub NEO-FFI - kwestionariusz osobowości autorstwa Costy i Mccre (1992), bazującym na teorii “Wielkiej Piątki”. Innym sposobem, mniej psychometrycznym, mógłby być pomiar opierający się na określeniu liczby kontaktów towarzyskich nawiązywanych w ciągu określonego czasu lub liczby znajomych na social mediach. Od tego, w jaki sposób zbierzemy informacje, zależy jaką analizę statystyczną będziemy mogli zastosować do naszych wyników.
Jak myślisz, czy badając cechę ekstrawersji, dobrym pomysłem jest zadać osobom badanym pytanie Czy jesteś ekstrawertyczny/a?
Jak się domyślasz, nie :)
A czy może jakimś innym jednym pytaniem jesteśmy w stanie dobrze zbadać cechę ekstrawersji? np. “Czy lubisz rozmawiać z ludźmi?”
Nie! Na podstawie jednego pytania trudno byłoby uzyskać wnioski na temat poziomu ekstrawersji - nie jest to jednowymiarowe zjawisko, możliwe do zbadania jednym pytaniem. Gdy zadamy pytania odwołujące się do różńych sytuacji, emocji, uczuć, zachowań, planów itd. mamy szansę uzyskać obraz, który będzie pełniejszy i bardziej wiarygodny.
Wskaźniki
Dbając o rzetelność (czyli powtarzalność i stabliność pomiaru) zbieranych informacji nie bazujemy na pojedynczej obserwacji. Jedna cecha jest zwykle mierzona za pomocą kilku lub kilkunastu pozycji testowych, które razem tworzą skalę, dlatego potrzebujemy wskaźnika - nowej zmiennej w pliku z danymi, która podsumuje wyniki każdej osoby z wszystkich pozycji testowych.
Przykład: Załóżmy, że chcemy zbadać satysfakcję z pizzy. Nie możemy po prostu zapytać: „Czy jesteś usatysfakcjonowany z pizzy?”, bo to zbyt ogólne pytanie. Musimy więc rozłożyć to pojęcie na czynniki pierwsze, czyli określić, co składa się na satysfakcję.
Co mierzymy (podstawa teoretyczna): pizza neapolitańska z dowozem.
Nasze zmienne to: smak ciasta, brzegi, stopień wypieczenia, temperatura, czas dostawy, cena
Tworzymy pozycje testowe - stwierdzenia satysfakcji z pizzy:
- cienkie ciasto na środku -> “Pizza była cienka na środku”
- wyrośnięte brzegi -> “Brzegi były wyrośnięte i sprężyste”
- stopień wypieczenia -> “Pizza miała czarne bąble na brzegach”
- pizza dotarła ciepła -> “Pizza była zimna”
- cena vs. jakość -> “Uważam, że cena jest adekwatna do jakości”
Wszystkie możliwe odpowiedzi do pozycji testowych nazywamy kafeterią. Niech każda z tych odpowiedzi będzie oceniana w skali 1–5.
1 - zdecydowanie się nie zgadzam
2 - raczej się nie zgadzam
3 - ani się zgadza, ani nie zgadzam
4 - raczej się zgadzam
5 - zdecydowanie się zgadzam
Zsumowanie lub uśrednienie ich wyników stworzy wskaźnik ogólnej satysfakcji z pizzy – jedną zmienną, którą możemy dalej analizować w SPSS.
⚠️ Pamiętaj: Zmienna a wskaźnik Język metodologii mówi, że zmienna to pewna mierzona właściwość, a jej operacjonalizację (sposób pomiaru zmiennej) nazywamy wskaźnikiem. UWAGA! W SPSS zmienną nazywa każdy dokonany pomiar, dlatego w terminologii programu każdy wskaźnik jest zmienną (ponieważ przyjmuje zmienne wartości).
Pytania odwrócone
Jak możesz zauważyć jedna pozycja została skonstruowana w odwrotny sposób, przez tzw. inwersję. Tworzenie pozycji odwróconych jest dobre z kilku względów: unikamy ciągłego potakiwania ze strony badanego i niedokładnego czytania lub pomijania pozycji, licząc, że wybijemy osobę z bezrefleksyjego rytmu odpowiadania i uzyskamy efekt zastanowienia się nad odpowiedzią oraz by przedstawić osobie badanej inną perspektywę na problem (Hornowska, 2001).
Odwracanie skali
Nie polecamy tego robić ręcznie (czasochłonne i łatwo się pomylić) W SPSS mamy dwa sposoby na odwracanie skali.
- REKODOWANIE
- OBLICZ WARTOŚCI
I SPOSÓB - REKODOWANIE
W pakiecie SPSS są dostępne opcje REKODUJ NA TE SAME ZMIENNE i REKODUJ NA INNE ZMIENNE. Wybierając pierwszą opcję, tracimy dane surowe (a tego nie chcemy), dlatego wybieramy opcję drugą, tworząc nową zmienną.
Podążaj: Menu Pzekształcenia → Rekoduj na inne zmienne → wybierz zminą wynikową → wprowadź nazwę → przycisk zmień → przejdź do wartości źródłowe i wynikowe → zamień 1 na 5, 5 na 1, 2 na 4, 4 na 2 → przycisk dalej → OK.
Skale są odwrócone. W zakładce ZMIENNE znajdziesz je na końcu listy, w zakładce DANE zobaczysz, że zmienne mają odwrócone wartości w stosunku do swoich wyjściowych odpowiedników.
II SPOSÓB - OBLICZ WARTOŚCI
Ten sposób jest nieco szybszy i bardziej przydatny, gdy kafeteria odpowiedzi jest większa (np. zamiast 5 to 10). Stosujemy tutaj prosty wzór: (liczba stopni skali + 1) - (nasza zmienna)
Podążaj: Menu Pzekształcenia → Oblicz wartości → (w naszym przypadku) 6 - wybrana zmienna → OK.
Niezależnie od tego, jakim sposobem się posłużymy, efekt będzie taki sam.
Tworzenie wskaźnika
Po odwróceniu skal możemy przystąpić już do tworzenia wskaźnika. Będzie to zmienna, która podsumuje wyniki każdej osoby otrzymywane na wszystkich pozycjach kwestionariusza. Znów jest kilka sposobów, by to zrobić. Oto najbardziej popularne:
I SPOSÓB - UŚREDNIENIE PYTAŃ
Średnia to lepszy i częściej stosowany sposób, zwłaszcza, gdy stosujemy skale 5-stopniowe oraz, gdy mamy braki danych (osoba badana z niewiadomych przyczyn pominęła niektóre pozycje w teście).
II SPOSÓB - SUMOWANIE PYTAŃ
Suma lepiej sprawdza się przy krótkich skalach TAK/NIE.
Niezależnie od tego, czy chcemy uśrednić czy zsumować pytania, podżamy za: Menu Pzekształcenia → Oblicz wartości → nazywamy wskaźnik i do okienka Wyrażenie Numeryczne wpisujemy wzór, który stworzy nową zmienną → OK.
III SPOSÓB - ZLICZ WYSTĄPIENIA
Ciekawych odsyłam do Statystycznego Drogowskazu str. 124
📖 Słowniczek pojęć
SPSS (Statistical Package for the Social Sciences) – program do analizy statystycznej danych, szeroko wykorzystywany w naukach społecznych, psychologii i biznesie.
Zmienna (Variable) – cecha, którą badamy, np. wiek, płeć, wynik testu. W SPSS każda zmienna ma swoją kolumnę.
Wartość (Value) – konkretna liczba lub kategoria przypisana danej zmiennej, np. wiek = 23, płeć = 1 (kobieta).
**Widok ziennych* – zakładka w SPSS, gdzie definiujemy zmienne (nazwy, typy, etykiety, kody wartości).
Widok danych – zakładka w SPSS, gdzie wprowadzamy dane (wiersze = osoby, kolumny = zmienne).
Pytania odwrócone – inaczej inwersja, pozycja, w której znaczenie jest odwrotne względem pozostałych. Wymaga przekształcenia wartości, by interpretacja była spójna.
Rekodowanie – to jedna z podstawowych operacji na danych, jest to zamiana wartości zmiennej na inne (np. 1=„mężczyzna” → 0=„mężczyzna” lub w przypadku, gdy mamy w teście pozycje odwrócone).
Oblicz wartości – druga z podstawowych operacji na danych, przydatna, gdy chcemy stworzyć nową zmienną w przypadku pozycji odwróconych. Wzór: (liczba stopni skali + 1) - (nasza zmienna).
Wskaźnik zmiennej – zmienna stworzona na podstawie kilku innych (np. średnia z kilku pytań tworzy wskaźnik dobrostanu/ekstrawersji).